How to Build Scalable App Infrastructure for Future Growth and High Traffic
The viral success of an app can feel like a breakthrough moment – until backend systems collapse under the pressure of explosive growth. Sudden surges in users often expose architectural weaknesses that remain invisible during normal traffic conditions. Building a scalable app infrastructure, therefore, is not a reactive task but a proactive engineering discipline. It requires deliberate planning to ensure uptime, performance, and cost efficiency as user demand shifts from thousands to millions.
In a digital ecosystem where acquisition costs are steep and user expectations unforgiving, even brief performance degradation can trigger churn, negative reviews, and long-term reputational damage. True scalability goes far beyond adding servers; it involves designing systems that adapt gracefully to unpredictable traffic patterns while maintaining a seamless user experience.
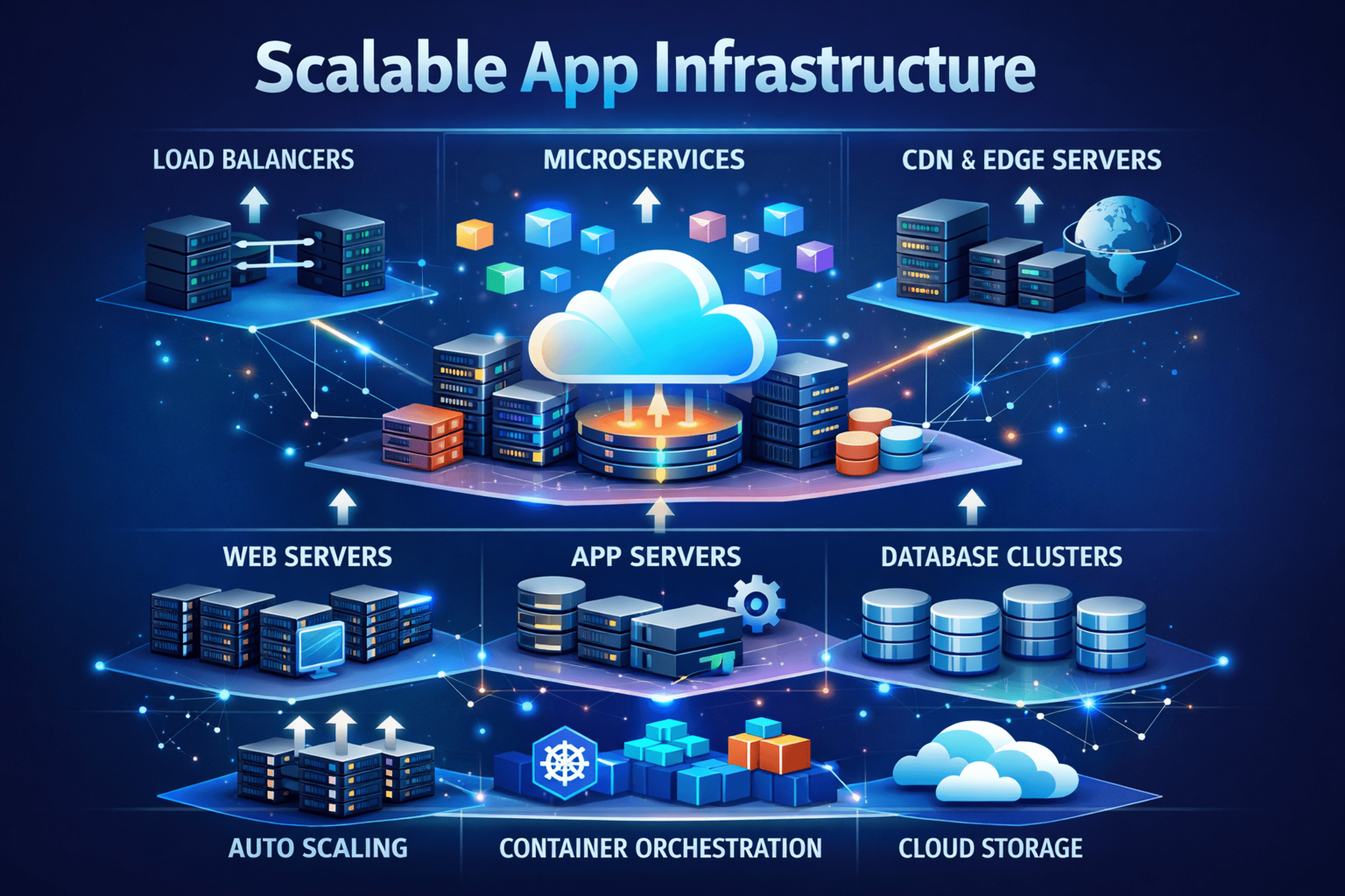
Understanding Scalability Beyond Simple Growth
Scalability is often misunderstood as the ability to handle “more users.” In reality, it is the capability of a system to maintain consistent performance under varying load conditions. Modern applications rarely experience linear growth. Traffic spikes driven by marketing campaigns, product launches, or viral exposure can multiply demand within hours.
A vertically scaled system – upgrading a single server’s power – may offer short-term relief but inevitably hits hardware limits and introduces single points of failure. Horizontal scaling, the foundation of modern infrastructure design, distributes workloads across multiple instances. This approach enhances fault tolerance, improves cost efficiency, and eliminates dependency on any single machine.
Instead of relying on a monolithic powerhouse server, horizontally scaled systems spread processing across numerous smaller nodes. If one node fails, others continue serving requests. This design philosophy directly improves reliability, availability, and performance stability.
Microservices and Modular System Design
Microservices architectures break applications into independent, loosely coupled services, each responsible for a specific function. Rather than scaling an entire application, individual services expand based on demand.
For example, authentication services may see load spikes during user sign-ups, while content services experience steadier traffic. Microservices allow targeted scaling, reducing wasteful resource allocation and enabling faster deployment cycles. Teams can update or optimize one service without risking system-wide disruption.
This modularity also improves fault isolation. A failure in one component does not necessarily cascade across the entire platform, strengthening overall resilience.
Serverless Computing for Dynamic Workloads
Serverless computing further refines scalability by abstracting server management entirely. Functions execute only when triggered by events, such as API requests or file uploads. Cloud providers automatically scale execution environments, often from zero to thousands of concurrent instances.
This model significantly reduces operational overhead and cost for unpredictable workloads. Compute resources are consumed only when needed, making serverless particularly effective for bursty or intermittent processes like image processing or background tasks.
However, serverless systems introduce considerations such as cold starts and state management. Latency-sensitive or long-running operations may still benefit from containerized or dedicated compute environments. Infrastructure decisions should align with performance requirements rather than trends.
Database Scaling and Data Layer Resilience
Databases frequently become the first bottleneck during rapid growth. Vertical scaling of a single database instance offers limited longevity. Horizontal strategies, such as replication and sharding, enable sustained throughput improvements.
Sharding partitions datasets across multiple database nodes, distributing read/write operations and preventing overload. While powerful, sharding increases operational complexity, particularly with cross-shard queries and schema changes.
Selecting the appropriate database type is equally critical. Relational databases excel at transactional consistency, while many NoSQL systems prioritize availability and horizontal scalability. Each application feature may impose different consistency requirements, necessitating deliberate trade-off evaluation.
Caching Strategies for Performance Optimization
Caching dramatically reduces latency and backend strain by storing frequently accessed data closer to users. Multi-layered caching – client-side, CDN, and server-side – forms a cornerstone of high-performance systems.
Client-side caching minimizes redundant asset downloads. CDNs distribute content across global edge nodes, reducing geographic latency. Server-side caches, using in-memory stores, accelerate data retrieval by avoiding repeated database queries.
Yet caching introduces the persistent challenge of invalidation. Poorly managed cache policies can serve stale data or create inconsistencies. Effective strategies balance freshness, performance, and system complexity.
Load Balancing and Auto-Scaling Mechanisms
Load balancers distribute incoming traffic across multiple compute resources, preventing localized overload and improving reliability. Health checks automatically reroute requests away from failing instances, maintaining service continuity.
Auto-scaling complements load balancing by dynamically adjusting capacity based on system metrics. Infrastructure expands during demand surges and contracts during low utilization, optimizing both performance and cost.
Improper tuning, however, can trigger instability. Scaling policies must consider instance warm-up times, cooldown periods, and application state management. Stateless designs simplify scaling operations and reduce disruption risks.
Multi-Region and High Availability Architectures
For mission-critical applications, deploying across multiple availability zones or regions safeguards against localized outages. Traffic routing mechanisms direct users to the nearest healthy environment, enhancing reliability and latency performance.
While multi-region architectures improve resilience, they introduce synchronization, replication, and operational challenges. Complexity increases alongside redundancy, demanding careful cost-benefit analysis.
Observability and System Intelligence
Scalable systems require deep visibility to remain performant. Observability integrates logs, metrics, and traces to reveal internal behavior and diagnose anomalies.
Logs provide granular event records. Metrics quantify system performance over time. Traces illuminate request flows across distributed components, exposing hidden latency sources or bottlenecks.
Together, these insights transform infrastructure management from reactive troubleshooting into proactive optimization. Synthetic monitoring and real-user data further strengthen understanding of real-world experience.
Security and Compliance at Scale
As infrastructure expands, security risks grow proportionally. Network segmentation, least-privilege access controls, and comprehensive encryption strategies form essential safeguards.
Sensitive data must be protected both in transit and at rest. Identity management frameworks prevent excessive permission exposure. Automated security configurations ensure consistency across scaling events.
Compliance requirements vary by application domain, making security architecture inseparable from scalability planning. Vulnerability scanning and audits remain continuous necessities.
Advanced Deployment and Resilience Practices
Deployment strategies influence both stability and innovation velocity. Immutable infrastructure eliminates configuration drift by replacing, rather than modifying, resources. Blue-green and canary deployments reduce rollout risk through controlled traffic exposure.
Chaos engineering validates resilience by intentionally introducing failures. These controlled experiments expose weaknesses before real-world incidents occur, strengthening systemic robustness.
Conclusion
Designing scalable app infrastructure is not a one-time achievement but an ongoing engineering practice. Systems must evolve alongside usage patterns, performance demands, and business objectives. Effective scalability embraces distribution, automation, observability, and resilience – while acknowledging inevitable trade-offs.
Infrastructure should be treated as a living system, continuously measured, refined, and stress-tested to ensure consistent performance under unpredictable conditions.
More Articles
How Can You Secure Your CMS Against Common Attacks and Data Breaches
Practical AI Deployment Best Practices Every Business Can Use Successfully Safely
Essential Checklist for Adopting Headless WordPress Trends That Improve Site Performance
A Practical Roadmap to Privacy Compliant Analytics Without Sacrificing Business Insights
FAQs
What’s the absolute first thing to consider when planning for a scalable app?
Start by focusing on your core architecture. Think modularity and separation of concerns from day one. Whether it’s a well-componentized monolith or a microservices approach, avoid building everything as one giant, tightly coupled block; that’s a nightmare to scale efficiently later on.
How can I prepare my application for unexpected traffic surges?
Implement auto-scaling and load balancing. Auto-scaling automatically adds or removes computing resources based on demand, while load balancers distribute incoming traffic evenly across multiple servers. Also, strategically using caching helps reduce the load on your backend systems, especially databases.
Is moving to microservices always the best way to achieve scalability?
While popular, microservices aren’t a silver bullet. They break your app into smaller, independent services, allowing you to scale specific parts that need more resources without scaling the entire application. This can be very efficient but also adds complexity in terms of deployment, monitoring and inter-service communication. Evaluate if the added complexity is worth the specific scalability benefits for your use case.
What role do databases play in a highly scalable infrastructure?
A massive one! A single database can quickly become a bottleneck. Strategies include using read replicas to offload read operations, sharding (distributing data across multiple databases) and sometimes even moving to specialized NoSQL databases for specific data models that require massive scale and flexibility beyond traditional relational databases.
How do cloud providers help with building scalable applications?
Cloud providers offer a ton of managed services that simplify scalability. Features like serverless functions (e. g. , AWS Lambda, Azure Functions), managed databases, content delivery networks (CDNs) and built-in auto-scaling capabilities mean you don’t have to manage the underlying infrastructure yourself. This lets you focus more on your application logic and less on infrastructure operations.
Beyond just adding more servers, what other techniques boost performance for high traffic?
Besides horizontal scaling (adding more servers), focus on optimizing your code, database queries and data access patterns. Implement robust caching strategies at various levels (CDN, application, database), use efficient data structures and algorithms and leverage asynchronous processing for non-critical tasks. Constant monitoring helps identify and resolve performance bottlenecks.
What’s crucial for ensuring my app can grow globally?
For global growth, consider deploying your application in multiple geographic regions to reduce latency for users worldwide. Use a Content Delivery Network (CDN) to cache static content closer to your users. Also, design your data storage with regional data residency requirements in mind and ensure your architecture can handle distributed data effectively.