How to Design a Resilient Serverless Architecture for Reliable Applications
Building Resilient Serverless Architectures for High-Scale App Backends
Modern app users expect instant responsiveness and flawless stability. When backend systems fail, even briefly, the consequences are immediate: negative reviews, abandoned sessions, and lost trust. Serverless computing offers compelling advantages such as automatic scaling and reduced infrastructure management, but resilience is not guaranteed by default. Achieving reliability in a distributed, event-driven serverless environment requires intentional architectural design.
True resilience goes far beyond basic error handling inside individual functions. It demands a system-wide strategy addressing failure modes, latency variability, retries, data consistency, and recovery behavior.
Why Resilience Matters More in Serverless Systems
Serverless platforms abstract away server management, but they do not eliminate failure. Instead, failures shift from infrastructure concerns to application-level design challenges. Functions are ephemeral, services are loosely coupled, and communication often depends on networks and managed services, each introducing new reliability risks.
A single poorly designed interaction between components can disrupt entire workflows. For high-scale app backends handling authentication, downloads, transactions, or content delivery, resilience directly determines user experience and retention.
Resilience means systems continue functioning under adverse conditions and recover gracefully when disruptions occur. It is about maintaining integrity, responsiveness, and correctness even when components behave unpredictably.
Idempotency as a Foundation of Reliable Serverless Design
In distributed systems, duplicate requests are inevitable. Network retries, timeouts, and transient failures can trigger repeated executions. Without safeguards, this can produce serious issues such as double charges, duplicate records, or corrupted state.
Idempotency ensures repeated execution of the same request produces the same outcome. This principle is critical for operations with side effects, including payments, user creation, and updates.
A common mechanism involves client-generated unique identifiers. Each request carries a unique transaction or request ID stored and validated before processing. If the ID already exists, the system returns the previous result rather than re-executing logic.
For example, in an in-app purchase workflow, idempotency prevents duplicate payment attempts even if the client retries due to latency or timeouts. While this introduces minor overhead from lookup operations, it prevents far more costly inconsistencies.
Designing Atomic and Consistent Operations
Serverless functions often interact with multiple services. Partial failures can occur when one operation succeeds but another fails. Without atomic design, systems risk inconsistent data states.
Atomic operations ensure related changes either complete together or not at all. Techniques vary by datastore and architecture but often include conditional writes, transactions, or event-driven compensation patterns.
Reliable serverless architectures minimize multi-step dependencies inside synchronous flows. Breaking complex operations into isolated, event-driven stages reduces the risk of cascading inconsistencies.
Intelligent Retry Strategies for Transient Failures
Transient failures are common in distributed environments. Network delays, throttling, or temporary service disruptions can cause sporadic errors. Simply failing requests degrades reliability and user experience.
Retries are essential but must be implemented carefully. Fixed-delay retries can overwhelm recovering systems, worsening outages. Exponential backoff mitigates this by increasing delay intervals between retries. Adding jitter introduces randomness, preventing synchronized retry spikes.
Many serverless platforms provide built-in retry mechanisms for asynchronous invocations, but synchronous flows often require explicit design. Retrying intelligently transforms temporary disruptions into recoverable events rather than user-visible failures.
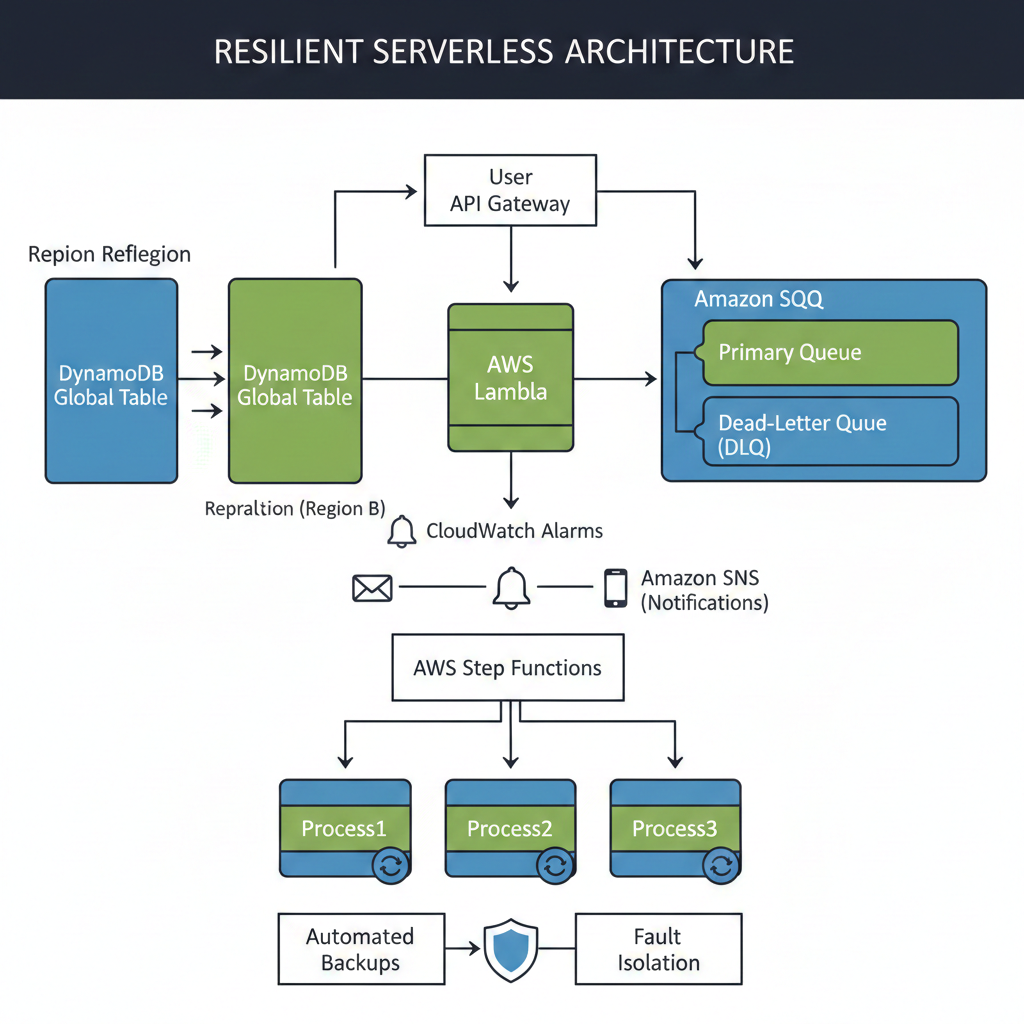
Dead-Letter Queues and Failure Isolation
Not all failures are recoverable through retries. Some events consistently fail due to data issues, schema mismatches, or logic errors. Dropping such messages leads to silent data loss.
Dead-letter queues act as safety nets for failed executions. When retries are exhausted, events are redirected for inspection and remediation rather than discarded. This preserves diagnostic visibility and enables corrective workflows.
For app backends processing critical data streams, DLQs are indispensable for maintaining integrity and operational insight.
Leveraging Asynchronous and Event-Driven Patterns
Decoupling components through asynchronous communication dramatically improves resilience. Instead of chaining synchronous calls, functions publish events to queues or streams. Downstream services consume events independently.
This design prevents failures in one component from blocking others. Consider a user registration workflow. Rather than executing email sending, analytics logging, and profile initialization synchronously, the system emits an event after user creation. Each concern is handled by separate consumers.
If a notification service fails, registration still succeeds. Users experience faster responses while failures remain isolated. Scalability also improves because each component scales based on its own workload.
The trade-off lies in debugging complexity. Distributed event flows require tracing and observability tools to maintain visibility.
Multi-Region Resiliency and Disaster Recovery
Serverless platforms provide high availability within regions, but regional disruptions, though rare, can still occur. Applications with global reach or strict uptime requirements benefit from multi-region strategies.
Active-passive architectures maintain a standby region for failover. This model simplifies operations but introduces brief recovery delays. Active-active deployments serve traffic across regions simultaneously, providing minimal downtime and improved latency distribution.
Data replication mechanisms such as globally distributed databases enable consistency across regions, though they introduce design complexity and higher costs. The choice depends on business criticality, latency sensitivity, and tolerance for recovery delays.
Observability as a Core Reliability Mechanism
Resilience cannot exist without visibility. The distributed nature of serverless systems obscures failure sources unless comprehensive observability is implemented.
Three pillars underpin effective monitoring: logs, metrics, and traces.
Structured logs provide searchable diagnostic context. Custom metrics reflect business-level health indicators such as success rates or latency distributions. Distributed tracing reveals how requests traverse services and where bottlenecks or failures occur.
Without these capabilities, troubleshooting becomes reactive and inefficient, increasing mean time to resolution and risking prolonged disruptions.
Chaos Engineering for Real-World Resilience Validation
Architectural resilience must be validated empirically. Chaos engineering intentionally introduces controlled failures to observe system behavior and uncover weaknesses.
Experiments may involve injecting latency, simulating dependency outages, or altering error rates. Each test begins with a hypothesis about system behavior under stress. Observations then confirm or invalidate assumptions.
This proactive approach identifies vulnerabilities before they affect users. While experimentation introduces risk, starting with small, controlled scenarios minimizes impact and strengthens confidence in recovery mechanisms.
Organizations practicing systematic resilience testing often experience reduced incident severity and faster recovery times.
Security as a Pillar of Resilience
Security failures are resilience failures. Vulnerabilities compromise availability, integrity, and trust. Serverless architectures require rigorous security design aligned with reliability objectives.
The principle of least privilege limits damage from compromised components. Input validation prevents malicious payloads. API throttling and Web Application Firewalls protect against abusive traffic patterns.
Integrating functions within private network boundaries reduces exposure. Regular updates and audits ensure defenses remain effective. A secure system is inherently more stable and trustworthy.
Embracing Failure as a Design Constraint
Failure is unavoidable in distributed systems. Resilient serverless architectures accept this reality and focus on containment, recovery, and graceful degradation.
Effective designs prioritize idempotency, fault isolation, intelligent retries, asynchronous workflows, observability, and empirical testing. Resilience becomes an emergent property of disciplined engineering rather than an accidental outcome.
When properly architected, serverless systems transform potential outages into minor operational disturbances invisible to end-users.
Conclusion
Serverless computing simplifies infrastructure management but heightens the importance of application-level reliability engineering. Resilience requires deliberate design decisions addressing duplication, latency variability, dependency failures, and recovery behavior.
Systems that recover quickly, preserve integrity, and maintain responsiveness under stress deliver superior user experiences and long-term business value. Mastering serverless resilience is not merely a technical exercise; it is a strategic necessity for modern digital applications.
More Articles
Practical AI Deployment Best Practices Every Business Can Use Successfully Safely
How Can You Secure Your CMS Against Common Attacks and Data Breaches
Essential Checklist for Adopting Headless WordPress Trends That Improve Site Performance
How to Optimize Product Pages That Increase Conversions and Improve Search Rankings
FAQs
What does ‘resilient serverless architecture’ actually mean?
It’s all about designing your serverless applications to keep working smoothly, even when things go wrong. Think of it as making your system robust enough to handle unexpected failures, errors, or high traffic without falling apart, ensuring it can recover quickly and gracefully.
Why should I even bother making my serverless applications resilient?
Making your serverless apps resilient is crucial for reliability. It means less downtime, happier users and fewer frantic calls in the middle of the night. It helps maintain data integrity, provides a better user experience and ultimately saves you time and money by preventing costly outages.
What are some common pitfalls or failure points in serverless that I need to look out for?
Watch out for exceeding service limits (like concurrent executions), dependencies on external services that might fail, sudden spikes in traffic, misconfigurations, and, of course, bugs in your own code. Event source failures, network issues and cold starts under heavy load can also be tricky.
How do I handle errors and make sure my serverless functions don’t just give up?
You can implement automatic retries for transient errors, often with exponential backoff. For persistent failures, use Dead-Letter Queues (DLQs) to capture and inspect failed events instead of just discarding them. Also, consider circuit breakers for downstream dependencies to prevent cascading failures.
Can I really make my serverless app survive if an entire cloud region goes down?
Yes, absolutely! By deploying your application across multiple cloud regions, you can achieve true disaster recovery. This might involve active-active setups where traffic is split, or active-passive where you have a standby region ready to take over if the primary fails. Just remember to replicate your data too!
How do I know if my serverless app is actually being resilient and not just pretending?
Solid monitoring and logging are your best friends here. You need to collect metrics on errors, latency and throughput and set up alerts for any anomalies. Practicing chaos engineering, where you intentionally inject failures into your system, can also reveal weak points before they become real problems.
What’s idempotency and why is it so crucial for resilient serverless applications?
Idempotency means that performing an operation multiple times has the same effect as performing it once. In serverless, where events can be delivered more than once (e. g. , due to retries), ensuring your functions are idempotent prevents duplicate data creation, incorrect state changes, or other undesirable side effects. It’s key for safe processing in an ‘at-least-once’ delivery world.