Unlock Business Value by Building Efficient Data Pipelines
The Strategic Imperative of Efficient Data Pipelines
In modern enterprises, data pipelines have evolved from back-end infrastructure into a see-it-or-feel-it competitive advantage. Organizations no longer build pipelines simply to move data; they design them to power real-time analytics, operational intelligence, and machine learning at scale. The core objective is reducing data latency so decisions can be made faster and with greater confidence.
Consider a retail or e-commerce environment. Traditional daily batch updates create unavoidable blind spots – inventory mismatches, delayed demand signals, and reactive decision-making. Shifting to low-latency pipelines, whether through streaming or micro-batching, compresses feedback loops from hours to minutes. The business impact is tangible: faster inventory adjustments, improved customer experiences, and more responsive pricing strategies.
Speed alone, however, is insufficient. Efficient pipelines also dismantle data silos, align business logic across departments, and establish a consistent source of truth. When sales, marketing, and finance rely on harmonized datasets, metrics such as customer lifetime value or revenue attribution become trustworthy. This consistency directly supports governance, forecasting accuracy, and executive decision-making.
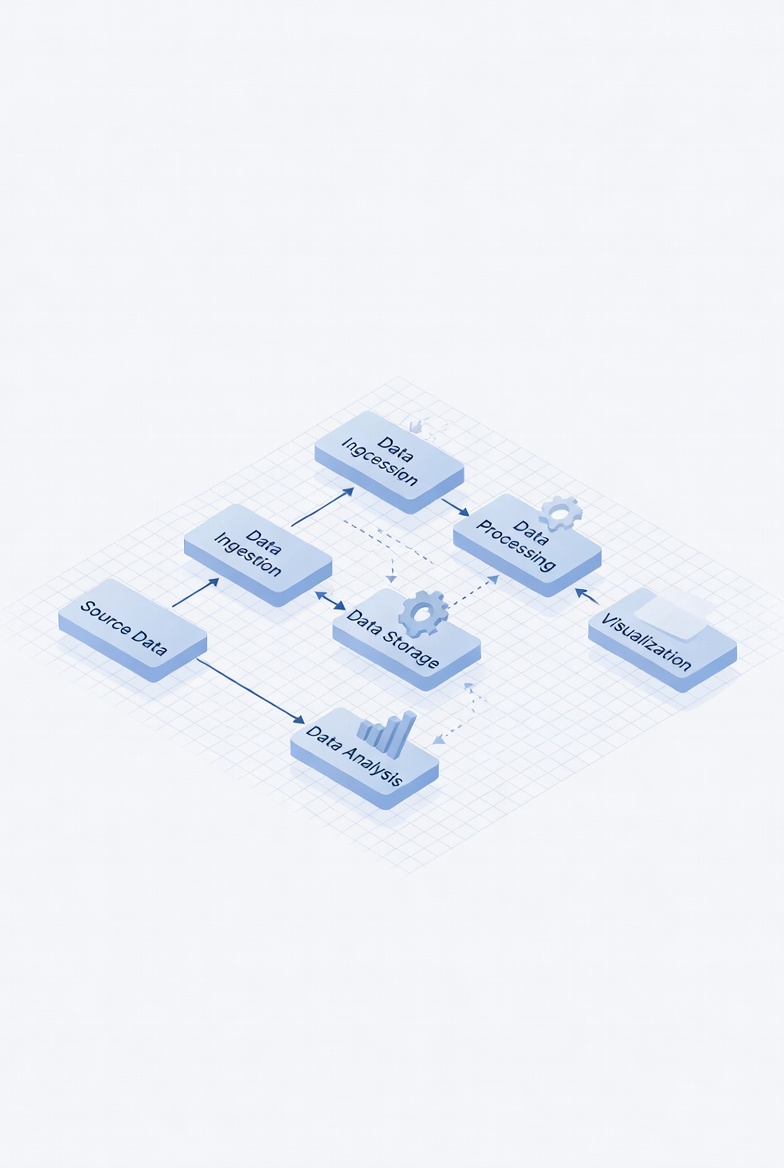
Deconstructing Data Pipelines: Core Architecture
Data pipelines generally follow three architectural patterns: batch, streaming, or hybrid.
Batch pipelines process data in scheduled intervals, making them cost-effective and suitable for historical reporting or non-urgent analytics. They rely on periodic extraction, transformation, and loading mechanisms that emphasize throughput over immediacy.
Streaming pipelines process events continuously as they occur. Built for low latency, they are essential for use cases like fraud detection, monitoring, and real-time personalization. Instead of waiting for accumulated data, streaming systems react instantly, enabling dynamic operational decisions.
Hybrid architectures combine both approaches. Streaming layers handle immediate processing and rapid visibility, while batch systems perform deeper aggregations or archival workloads. This balanced model often provides optimal efficiency, aligning technical design with business priorities.
Regardless of the pattern, robust pipelines typically include data sources, ingestion mechanisms, storage layers, transformation logic, orchestration systems, and consumption endpoints. Each component must be selected based on latency requirements, scalability needs, and operational complexity.
Data Ingestion Strategies: Latency vs. Cost
Data ingestion decisions shape pipeline performance more than most organizations initially realize. The fundamental trade-off is between freshness and resource efficiency.
Batch ingestion uses scheduled jobs, file transfers, or API polling. It is simple and economical but introduces inherent delays. For reporting or compliance workloads, this latency is often acceptable and financially prudent.
Streaming ingestion captures data continuously, often via event streams or change data capture mechanisms. It delivers near real-time visibility but demands always-on infrastructure, careful scaling, and deeper monitoring. Streaming should therefore be driven by genuine business needs rather than technological enthusiasm.
The most effective ingestion strategy is not universally real-time. It is context-aware. High-value operational signals may justify streaming, while lower-priority datasets remain ideal for batch processing. Over-engineering for immediacy can inflate costs without proportional benefit.
Transformation Paradigms: ETL vs. ELT
Data transformation is where raw inputs become usable assets. Two dominant paradigms guide design choices.
Traditional ETL transforms data before loading it into analytical systems. This enforces structure early but can limit flexibility and complicate schema changes.
ELT reverses the sequence, loading raw data first and transforming it within scalable analytical platforms. This model supports agility, version control, and iterative modeling. Modern transformation workflows increasingly emphasize modular logic, reproducibility, and automated testing to safeguard data quality.
Embedding validation checks early prevents downstream failures and reduces debugging overhead. Reliable transformation layers turn pipelines from fragile workflows into dependable business systems.
Orchestration & Observability: Ensuring Reliability
As pipelines grow in complexity, orchestration becomes indispensable. Workflow engines coordinate dependencies, retries, scheduling, and failure recovery. Without structured orchestration, even well-designed pipelines degrade into brittle, manual processes.
Yet orchestration alone does not guarantee reliability. Monitoring and observability complete the picture. Metrics such as latency, throughput, freshness, error rates, and consumer lag reveal system health. Aggregated logs and tracing mechanisms expose root causes rather than surface symptoms.
High-performing data systems are not those that never fail – they are those that detect, diagnose, and recover quickly. Proactive alerting and performance tracking transform incidents from disruptive surprises into manageable events.
Advanced Evolution: Real-Time Systems & ML Integration
As organizations mature, pipeline objectives expand beyond reporting. Real-time analytics enables instantaneous reactions to behavioral signals, operational anomalies, or customer interactions. Stream-processing architectures simplify this shift by un seeifying historical and live processing models.
Machine learning integration introduces another layer of sophistication. Pipelines must now support feature generation, training cycles, inference workflows, and model monitoring. The emphasis shifts from static datasets to continuously evolving predictive systems.
These capabilities increase architectural complexity but unlock powerful business outcomes: personalization, automation, and predictive decision-making.
Decentralization & the Rise of Data Mesh
Traditional centralized data ownership can become a bottleneck in large organizations. The Data Mesh paradigm decentralizes responsibility, assigning domain teams ownership of their data products.
Each domain manages, documents, and exposes its datasets through standardized interfaces and reliability guarantees. This approach improves scalability and agility but requires strong metadata management and interoperability frameworks to maintain coherence across the ecosystem.
The shift is as organizational as it is technical, redefining how teams collaborate around data assets.
Securing & Governing Data Pipelines
As pipelines carry increasingly sensitive information, security and governance become foundational rather than optional. Encryption, secure communication protocols, and granular access controls protect data throughout its lifecycle.
Sensitive data handling techniques – masking, anonymization, tokenization – reduce compliance risks and preserve trust. Governance mechanisms such as lineage tracking, cataloging, and audit trails ensure transparency and accountability.
Effective governance strikes a balance: protecting critical assets without obstructing legitimate analytical work.
Measuring Success & Driving Continuous Improvement
Efficient pipelines are defined by outcomes, not deployment. Key performance indicators such as data freshness, accuracy, latency, reliability, and cost efficiency reveal whether pipelines deliver genuine value.
Continuous monitoring, performance profiling, and iterative optimization sustain improvements over time. Bottlenecks emerge, workloads evolve, and business priorities shift. Pipelines must therefore adapt just as software systems do.
Automation through version control, testing frameworks, and deployment workflows accelerates iteration while reducing operational risk. The long-term advantage lies in refinement and resilience rather than initial design alone.
Conclusion
Data pipelines represent far more than technical plumbing. They are the operational backbone of analytics, intelligence, and decision-making. Their true value emerges from careful architectural choices, disciplined monitoring, and relentless optimization.
Organizations that treat pipelines as living systems – measurable, observable, and continuously improved – transform data from a passive asset into a persistent engine of business advantage. In a landscape defined by speed and scale, stagnation is not neutral; it is a liability.
More Articles
How to Streamline Your IT Workflows for Maximum Business Efficiency
Your Roadmap to Calculating Automation ROI and Justifying Its Value
How to Design a Resilient Serverless Architecture for Reliable Applications
How to Back Up Your vital Computer Files Safely and Reliably
Public Cloud Versus Private Cloud Which Option Suits Your Business Best
FAQs
What exactly is a data pipeline?
A data pipeline is essentially a series of steps that move raw data from various sources, transform it. load it into a destination where it can be analyzed or used. Think of it as a conveyor belt for your data, making sure it gets where it needs to go in the right format.
Why should my business care about efficient data pipelines?
Efficient data pipelines are crucial because they ensure you get timely, accurate. relevant data to make better business decisions. Without them, your insights could be delayed, incomplete, or even wrong, leading to missed opportunities or poor strategic choices.
How do efficient data pipelines actually help unlock business value?
They unlock value by enabling faster access to reliable data for analytics, AI. reporting. This means quicker insights into customer behavior, operational efficiency, market trends. product performance, allowing you to innovate faster, optimize processes. gain a significant competitive edge.
What are some common problems with inefficient data pipelines?
Inefficient pipelines often lead to a messy situation: data quality issues, delayed reports, increased operational costs due to constant manual fixes. a general lack of trust in the data. This can severely hinder strategic decision-making and slow down overall business growth.
What does ‘efficient’ really mean when we talk about data pipelines?
When we say ‘efficient,’ we mean your pipelines are reliable, highly automated, scalable to handle growing data volumes, cost-effective to run. consistently deliver high-quality data with minimal latency. They should process data quickly and accurately without excessive manual effort or resource consumption.
Do only large companies benefit from robust data pipelines?
Not at all! Businesses of all sizes can benefit immensely. Even smaller companies can gain a significant advantage by automating their data flow, ensuring they have a clear, real-time view of their operations, sales. customer interactions to make smarter, data-backed choices and stay competitive.
What kind of business outcomes can I expect from investing in better data pipelines?
You can expect a range of positive outcomes, including improved operational efficiency, enhanced customer experiences, more accurate forecasting, faster time-to-market for new products and services, reduced business risk. ultimately, increased revenue and profitability through truly data-driven decisions.